
Web Development:
Current Good Practices
Five good practices need to be promoted now, if we Web developers are to unleash the full power of our technology:
- formal validation of HTML files
- separation of content from presentation - on the one hand through the creation of CSS files for appropriate visual effects, on the other through the creation of HTML files friendly even to text-only browsers
- adoption of disciplined information architectures for collections of Web pages
- tight integration of Web and press publishing
- participation in the public Web-accessibility initiatives
Formal validation of HTML files begins
with the machine-directed declaration of an HTML standard at the
beginning of each file, explicitly telling servers and browsers not
only that the given file is an HTML document, but to which Document
Type Definition (DTD) the document is intended to conform. At present
(late in 2002), it suffices to choose XHTML 1.0 Strict - a standard
that is, with the exception of its prefatory lines, tag-for-tag
identical with HTML 4.01 Strict. Specifying HTML 4.01 Transitional, or
some earlier HTML, such as HTML 3.2, is not quite ideal, since the
World Wide Web Consortium (W3C) is for good reasons now moving
toward the abandonment of (formally, "deprecating") some
of the 1990s tags, including the once-ubiquitous
<FONT>. While intelligently written XHTML 1.0 Strict
is backward-compatible, yielding acceptable results
even in older browsers, the
old HTML versions are not guaranteed to remain forever compatible
with browsers tailored to future (X)HTML standards.
This means, in particular, that if we are generating our HTML with
page-coding software, rather than with an all-purpose editor such as
Unix emacs or Unix vi, we need to ensure correct configuration of the
software: the software must write an incantation like
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> (with
some further prefatory material specifying an XML namespace).
In striving to write strictly correct HTML code, we need a book explaining the full theory of the tag structures. The job is done well by the fourth edition of Chuck Musciano and Bill Kennedy's HTML & XHTML: The Definitive Guide (O'Reilly, 2000).
With our HTML duly coded, we need to check validity. If we have uploaded our page to some public server, we can supply the URL to the online validity-checker at W3C, using self-evident links from http://www.w3c.org. Alternatively, if we are running the Opera browser - available in both payware and no-functions-lost freeware versions from http://www.opera.com - we can make a Linux third-mousebutton click in the displayed page, and then select menu items "Frame -> Validate source...". The latter strategy has the advantage of working even if we are viewing the page on our own local workstation, before uploading it to a public server. In both cases, we shall either be told that the page conforms to our declared DTD or be told what specific tags are nonconformant.
A check of well-known pages on the Web reveals astonishing quantities of illegal HTML. A pleasant occasional five-minute recreation for the publishing professional, and one which benefits the wider community, is the checking of well-known pages with a validating tool. If, as is almost always the case, we find errors, we can send a quick, friendly mail to the webmaster, perhaps a little pointedly praising the efforts of W3C in bringing law and order to the Internet!
Further, we do well to place the W3C valid-HTML badge at the foot of our page, hyperlinked to the Consortium's validating parser. Displaying the badge declares openly that our page is legally tagged, and so makes it evident to everyone that our design ideas are worth cloning. Moreover, making the badge a hyperlink to the validating parser means that we ourselves, and the commercial client buying pages from us, and the properly skeptical member of the surfing public, have only to click on the badge to test future uploaded versions of the page for validity. (There are pretty well bound to be future versions, if only because text gets revised as fine details in the underlying journalistic message change. Murphy's Law being what it is, we may well expect that we, or the people to whom we have sold our services as an Internet consultant, or the unknown third parties who have cloned our design ideas, will someday misplace an HTML tag in the act of revising, and so will inadvertently upload an illegally tagged, seemingly good-looking, page to the server.)
Separation of content from presentation
primarily involves creating an entire HTML page as content,
without presentational markup, and using a separate Cascading
Style Sheet file to guide the browser in applying appropriate fonts,
background colours, and similar typographic decoration. Here again, an
O'Reilly paperback from the year 2000, this time Eric A. Meyer's
Cascading Style Sheets: The Definitive Guide, gives a thorough
briefing on the underlying theory. When the job is done correctly, the
HTML file itself has no presentational elements at all - not even the
<TABLE> tag so heavily used by 1990s designers, in
texts without true tables, to shoehorn page elements into the right
spots. (At any rate, my own design philosophy eschews tables. Others
may feel differently. I take this element in my philosophy from CSS
evangelist Dominique Hazaël-Massieux, who supplies a
do-it-without-any-tables tutorial at http://www.w3.org/2002/03/csslayout-howto.)
Admittedly, many browsers do not support CSS adequately. My reading
and experiments suggest that it is best not to expect the Netscape 4.x
family to cope with CSS.
We can make Netscape 4.x unaware
that CSS styling has been applied, while drawing the CSS to the
attention of Internet Explorer 4.0 and above,
Opera, Mozilla, Netscape 6.x, Netscape 7.x, and the
like: Netscape 4.x is conveniently blind to the invocation
<style type='text/css'> @import url('foobar.css');
</style>.
If we want to be more sophisticated (I haven't been there yet, but
perhaps I ought to go), we can reveal selected aspects of CSS for the
benefit of Netscape 4.x, while concealing others. Details are available
from http://www.ericmeyeroncss.com/bonus/trick-hide.html.
Further, both my reading and my experiments indicate serious problems with at least the earliest of the Internet Explorer 5.x family. But here the problems are not so severe as to preclude applying CSS. It is enough to be wary, paying the painful price of suppressing display of bullets in unordered lists, and bracing oneself for the possible need to render paragraphs without indention.
The ultimate response to the diverse insectarium of browser bugs is the incorporation of a JavaScript sniffer in one's HTML code, so as to detect the manufacturer and version number of each server-interrogating browser, and to serve out one or another CSS stylesheet as appropriate in the given case. (It's not, alas, an approach I know anything about.) In particular, one could, while serving substantial CSS to Explorer 5.x, serve not only bulleted lists, but traditional fine book typography, to all and only the CSS-aware browsers identifying themselves to the sniffer as superior to Explorer 5.x. Fine typography might include the following: no extra interparagraph whitespace; the first line of each paragraph indented by a single em, except where the paragraph opens a section; the first line of each section-opening paragraph set flush left; some or all section openings embellished with a large initial cap, the rest of that line being further embellished by rendering in small caps. (Maybe I'll get that far next year with these pages, maybe not.)
CSS, once we get it to work, delivers an immediate benefit, long before we need its well-known advantages in text-to-speech browsing and handheld-device (PDA) display. Since CSS allows presentation directives to reside in a file separate from all our HTML files, we can adjust such a detail as headline colour, in a two-hundred-page site with a thousand headlines, by changing a single stylesheet line. That, in turn, makes us bolder in experimenting with the look of our pages, and so is in the long run liable to improve our professional taste in typography.
Not only the HTML code in a page, but also the accompanying CSS, needs validation. In this case, too, a validating tool, with a validity-proclaiming badge, is available at http://www.w3c.org.
Primarily, then, separating content from presentation means separating plain HTML from CSS. Secondarily, it means designing even the plain HTML to meet the needs of all readers - so as to accommodate not only those using text-to-speech browsers (certainly the blind; possibly, too, the eventual purchasers of some "Web Walkman"), but also, more subtly, those using the emerging low-graphics wireless text-display devices, such as networked PDAs or Web-connected cell phones.
In the best of all possible worlds, we Web developers would run some such tool as the IBM Home Page Reader (HPR) synthesized-voice browser, for checking that our pages meet even the most exacting requirements of text-only publication. Failing that, we can at least check our work in the text-only visual browser lynx. Here's how lynx looks on my own (Mandrake Linux) workstation:
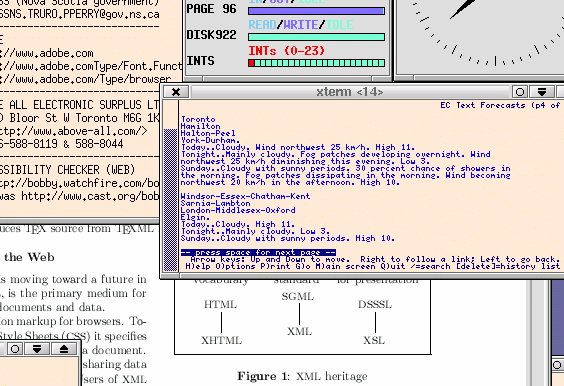
Reproduced here is a small piece of one screen from my four-screen environment, showing at this particular instant in the workflow the bottom edge of a (time-server-synchronized) clock, the bottom edge of the system-monitoring xosview tool, the left edge of a home-made address book maintained with the plain-text vi editor (why waste time on address-book bloatware?), a portion of an xpdf viewer, two minuscule xterm chunks, a tiny chunk of the navy-blue desktop surface, and pretty well all of lynx.
In this
particular case, lynx has been launched in a tiny-font xterm, with the
command-line invocation wea, so as to bring up the
Toronto weather forecast at or very near the Universal Coordinated
Time 20021026T153417Z.
(wea is my own shorthand, strictly a "bash
shell alias", implemented with the .bashrc configuration-file line
alias 'wea=lynx -term=vt100
http://weatheroffice.ec.gc.ca/foo/bar' for an appropriate
foo/bar. The shorthand is useful when we want the weather
forecast in a hurry, and do not wish to take the several seconds
needed for mousing to, and activating,
a weather bookmark in a conventional browser
such as Netscape or Opera.)
If we do not have lynx installed on our own workstation, we can find a
public-access client by giving Google the search string public
lynx.
If you are reading this present page in a conventional browser with
image downloading enabled, you will find a pair of adjacent clickable
icons at the bottom of the page, leading to two different validation
engines at W3C. Following my
own exhortation to
make pages display cleanly in text-only browsers, I have chosen to
code the HTML for the two icons with alt attributes on
the img tags, with square brackets in the attribute text:
alt="[Valid XHTML 1.0!]" for the first image, and
alt="[Valid CSS!]" for the second. This pair of decisions
has the consequence that a text-only browser displays [Valid
XHTML 1.0!] [Valid CSS!] - or, conceivably, in the worst
possible case, the no-intervening-whitespace
[Valid XHTML 1.0!][Valid CSS!] - but with
no risk of displaying the repellent Valid XTHML 1.0!Valid
CSS!. In addition to being effective separators, the square
brackets reinforce the suggestion of clickability already incorporated
into the standard lynx hyperlink look-and-feel.
The idea of using square brackets comes from an excellent essay on
the alt= attribute
by computing-for-physics specialist A.J. Flavell of
Glasgow University. (The essay was originally published
at http://ppewww.ph.gla.ac.uk/%7Eflavell/alt/alt-text.html,
was subsequently published in an authorized reprint
at http://www.htmlhelp.com, and was
also misappropriated elsewhere - in at least one case with an
assertion of copyright! - by third parties on the Web.) Flavell
stresses that alt= is normally to be used not to supply a
textual description of an image, but, rather, to supply text which in
a lynx-like environment serves the same function as the corresponding
image serves in a conventional browser.
Among Flavell's examples of
what can go wrong when his precept is ignored are the lynx-style
rendering "Small red bullet Response to Terrorism" for a page at the
American Embassy in Belgrade (what was needed was not alt="Small
red bullet", but alt="*") and the splendidly
sinister Britishism "Our Classroom and Staff fancy horizontal rule"
(what was needed was not alt="fancy horizontal rule", but
alt="________").
In many cases, an image is purely decorative, and so needs to be
dropped without any comment at all in lynx. In such a case, the
correct code is not, as it were, alt="decorative image of a
fancy open book on an oak table", but merely
alt="". (Why not leave out alt= altogether?
That minimalist tactic,
apart from being illegal in at least XHTML 1.0 Strict,
may cause a text-only browser to mark the place
of the image with a string such as IMG.
Such a string will lead some
readers to worry about the possible loss of editorially significant
visual content.)
Manufacturers of conventional browsers tend to render
alt= as mouseover text, in the style of "Tooltips" in a
Microsoft application. This is contrary to the actual
W3C intent of the
alt= construction. (It is, on the other hand,
an eminently
appropriate use of the attribute title=, permitted
with the
img tag in at least the HTML 4.01 and XHTML 1.0 family of
standards.)
Not only <img alt=, but also
tabular matter, used to present
problems for nonstandard browsers. Such matter is for two reasons less
problematic nowadays: on the one hand, current Web
development best practice (arguably) uses CSS in place of
<TABLE> to shoehorn the images on an elaborate page
into the places required by the full-dress visual presentation; and,
on the other hand, lynx (as one browser, at least,
in the text-only family) has (at least) a partial
understanding of <TABLE>. Still, problems may
remain. A useful resource, updated as recently as Universal
Coordinated Time 20020517T121011Z, is A.J. Flavell's "TABLES on
non-TABLE
Browsers" (http://ppewww.ph.gla.ac.uk/~flavell/www/tablejob.html).
Adoption of disciplined information architectures for collections of Web pages makes it easy for the surfer to find information. In the most interesting phase of my 1990s career as a part-time Web project manager, I worked hard with two talented designers, Tim Jancelewicz and David McCarthy, on the design of a technical site for a Government of Greenland agency. How could field engineers be sure to lay their hands quickly on mineral-blasting permits and similar agency documents? How could the site create a uniform surfing experience for readers of English, Greenlandic, and Danish, even given that the content in the three languages was not always identical-save-for-translation? After much thought, we evolved some principles (I will here disregard our special ideas for accommodating three languages) which I use today on my own http://www.interlog.com/~verbum/:
- Site content is to be organized into a conveniently small set of mutually exclusive, jointly exhaustive theme sections, each with its own introductory page, with each introductory page linked to a continually visible left-margin navigation button.
- Each theme section is to have its own theme graphics, to help surfers form a vivid mental map. (For this particular government agency, we chose cheerfully green highlights for pages relating to a community-outreach initiative, highlights in hydrocarbon brown for pages relating to petroleum drilling, and so on.)
- To avoid blurring the mental map, the number of links joining a pair of "subsidiary", or non-introductory, pages from two distinct theme sections is to be kept low. For the same reason, pages within any one theme are not to be organized into a randomly interlinked structure, but essentially into what mathematicians call a tree - with editorially prominent parent-to-child links, but with relatively few links between siblings, between cousins, or between more distant relatives. (In practice, this linking philosophy means thinking with the mind of a structural editor, or information architect. We work out, with an eye to the underlying journalistic message, what slabs of content intrinsically require, for instance, to be presented as logically subordinate one to the other, as parent and child, and what slabs of content intrinsically require to be made logically coordinate, as siblings. Content is the king that dictates the design details.)
- Each page is to have, near its top edge, a "parent > child" chain of hyperlinks to other pages in the same theme section, plus the homepage, in the approximate style "YOU ARE ON: home > fish stocks > halibut > halibut quotas and permits" or "YOU ARE ON: home > fish stocks > halibut > halibut quotas and permits > winter 2003 halibut permit-application form". (This specific example is, admittedly, hypothetical, since our agency worked in an area other than fisheries.)
Tight integration of Web and press publishing consists in allowing authors to write just once, and yet to publish both to the PDF viewer (or to the PostScript viewer, or to the offset press) and to the HTML browser.
I first explored Web-and-press integration in 1999, coding much of a 700-page Estonian-language book draft in SGML. In those days, the preferred markup language was SGML-based DocBook, and OpenJade the preferred tool for converting DocBook into the finished presentation. A tiny Linux bash script conveniently drove my Jade and a couple of pieces of auxiliary open-source software, generating, from the DocBook source code, a set of interlinked HTML pages on the one hand, and on the other hand a PostScript file ready for a PDF distiller.
The same technology has been used by document engineers in Paris, at least in 2001 or 2002, to produce the "User" and "Reference" manuals for Mandrake Linux.
Underlying the creation of a presentation for Web or press from DocBook source code via Jade is a stylesheet file in Document Style Semantics and Specification Language (DSSSL). Awkwardly, however, DSSSL syntax is alien to SGML, deriving instead from the 1960s artificial-intelligence language LISP, and therefore ultimately from the 1930s "lambda calculus" of American mathematical logician Alonzo Church. With the advent in the late 1990s of the machine-streamlined SGML subset XML, with the reformulation of DocBook markup in XML, and with the rise of XSL Formatting Objects (XSL-FO), a new Web-and-press integration technology has emerged.
Under this new technology, people continue to author in DocBook (admittedly, now in its XML, not its SGML, flavour). In place of Jade, however, they now run so-called XSL Transformations (XSLT) against the DocBook source file, with some such tool as the Xalan XSLT processor. One invocation of XSLT generates a set of XHTML pages. Another invocation generates what is essentially high-level printing-press markup, in XSL-FO. Finally, an invocation of some such tool as the Apache XML Project's open-source FOP generates PDF, ready for shipping to the lithographic-plate crew at the press house, from the XSL-FO. It's a technology I have not used yet, but which I look forward to exploring over the coming months.
At the moment, I've just begun investigating an XML alternative to the DocBook DTD, the Text Encoding Initiative (TEI; http://www.tei-c.org/). TEI started in 1987 in SGML, but has since diversified into XML. Whereas DocBook is the appropriate DTD framework for computer manuals and similar technical documents, TEI is suitable for the humanities. (TEI has applied its accumulated wisdom even to the more challenging problems in humanities scholarship, such as the analysis of medieval manuscripts. Gratifyingly, among the four universities guiding TEI is Oxford, a longstanding citadel of lexicography and philology.) Like DocBook, TEI is evidently an appropriate archiving technology for documents that get rendered via XSLT into printing-press and HTML publications.
Participation in the public Web-accessibility initiatives begins with an awareness of the work of the W3C (http://www.w3c.org). W3C was founded in 1994 by the CERN physicist Tim Berners-Lee, who devised the HTML-powered Web as an application of SGML. Today, W3C has more than 450 member organizations. The universities in the guiding-and-facilitating core include the Massachusetts Institute of Technology. It is W3C that promulgates the formal standards, such as XHTML 1.0 Strict, against which we validate our code.
Not only, however, does W3C construct formal Web engineering
standards: the Consortium has now also launched the Web Accessibility
Initiative (WAI). WAI promulgates a set of Web
Content Accessibility Guidelines (WCAG), with prioritized
quality-control "checkpoints". WAI and WCAG meet the concerns of
Section 508 in the Rehabilitation Act (USA) of 1973, and so supply an
appropriate framework for those Web developers seeking government
contracts. (Here in Canada, for instance, the Treasury Board has
issued the directive, "All GoC Web sites must comply with W3C Priority
1 and Priority 2 checkpoints . . . " It is no
doubt thanks to that directive that the Environment Canada weather
report proves readable when I
hastily launch lynx in a Linux xterm by typing
the command wea.)
As W3C supplies badges for declaring one's compliance with XHTML and CSS standards, so also it supplies a badge for asserting compliance with WAI-WCAG. Although I have not yet subjected my site to the WAI-WCAG checkpoint list, I hope to do so.
Perhaps second only in importance to WAI-WCAG is the grassroots "Web Standards Project", at http://www.webstandards.org/. Here we find an impressive combination of impassioned advocacy with the same clearheaded websmithing praxis as hallmarks http://www.w3c.org/ - pages implemented in CSS, with elegant typography, and maintained with fine engineering. (The site "Colophon" page gives the essentials of the engineering, in terms which show how much I, for one, need to learn, most notably about the Web-maintenance potential of Perl:
The site is written in XHTML Strict with Cascading Style Sheets (CSS). Several Perl scripts were used to create the site's directory structure and do the dirty work of copying templates and includes to their proper places before we could begin to populate the site with content. . . . The site is served by the Apache Web server, on a handmade Pentium III/400 running Linux. . . . We use the Concurrent Versions System, as well as various other CVS clients, to allow the geographically disparate members of the group to edit and manage the site.
Among the achievements of the Web Standards Project is the creation, in 2001, of a Macromedia Dreamweaver Taskforce. Thanks in part to the Taskforce, the Macromedia Dreamweaver MX which was released to the Web-developer community in May of 2002 is substantially more standards-aware than its predecessors.
Also eminently worth mentioning is the Web Design Group (WDG), which has for some years promoted the creation of "non-browser specific, non-resolution specific" pages. The WDG site, http://www.htmlhelp.com/, offers tools, including a link-checker, and a CSS validator that proves somewhat more user-friendly than the corresponding tool at W3C.
A lone crusader for Web usability and standards compliance, but now with allies publishing in 30 languages, from Afrikaans to Vietnamese, is the young American Web developer Cari D. Burstein, at http://www.anybrowser.org/.
Among the books on conservative design philosophy is the deeply thoughtful Web Style Guide, created by specialists in medical publishing at Yale. The hoary first edition (tailored to Netscape 2.x and Explorer 2.x, but nevertheless of continued utility on many points - especially, perhaps, on the eternally vexed question of browser-window widths) is still available at http://info.med.yale.edu/caim/manual/contents.html. The second edition (which I have not seen) can now be had from Amazon.
Finally, we remark that on the topic of Web accessibility, as on most topics, the volunteer editors at "Directory Mozilla", or the Open Directory Project, have amassed annotated bibliographies. (ODP can be browsed either as a downstream resource, through the Google "Directory" facility, or directly, at http://www.dmoz.com/.) At or very near Universal Coordinated Time 20021026T152837Z, two categories to check were Top: Computers: Software: Internet: Clients: WWW: Browsers: Accessibility and Top: Computers: Internet: Web Design and Development: Web Usability.
If you share my view that good Web engineering matters, then do get in touch. The most efficient means of communication is an e-mail to verbum@interlog.com, with a subject header incorporating the phrase "HTML good practices".